
ICON[1]是我转到马普所(MPI-IS)读博后,完成的第一篇工作,也是目前我的发表中,自己最喜欢的一个。因此,我想多花一点时间,讲一下这个工作的来龙去脉。这当然是一篇学术宣传稿,但却是真诚的。本文不是原文直译,而更像是一个概括及延展。除了厘清本研究的动机及思维起点(motivation);梳理出这二十多页论文的主线;我也会讲点“电视台不让播的”,比如论文中没提及的洞见 (insight),并着重讲一下ICON的局限及改进思路。
围绕“姿势水平(洋文: pose robustness)“,我会用“我今天算是得罪你们一下“,“为什么要提高姿势水平”,“如何提高姿势水平的”,“把我批判一番”,“历史的进程”这五个章节,来讲一下ICON的过去现在和将来。
先把几个链接放一下:Code | Colab | Homepage | Paper | Video
多说一句,Google Colab支持上传并测试你自己的图片,最后会生成类似下图这样的重建视频,你可以将视频上传到twitter并打上#ICON的标签,@yuliangxiu,无论结果是好是坏,我都会转发,对于重建任务,cherry picks和failure cases都是算法的一部分,好的烂的都放出来,才是一次完整的作品呈现,期待大家奇形怪状的重建结果。另外,Readpaper这个产品非常吼,大家如果有关于ICON的问题,可以直接在Readpaper上提问。

我今天算是得罪你们一下
首先,明确ICON的任务:给一张彩色图片,将二维纸片人,还原成拥有丰富几何细节的三维数字人。
围绕这一任务,之前有许多基于显式表达的方法 (expliclit representation: mesh[2], voxels[3], depth map & point cloud[4], etc),但直到三年前PIFu (ICCV19)[5]第一个把隐式表达 (implicit representation) 用到这个问题,衣服的几何细节才终于好到——艺术家愿意扔到Blender里面玩一玩的地步。但PIFu有两个严重的缺陷,速度慢+姿势鲁棒性差。我们在MonoPort(ECCV20)[6]中一定程度上解决了“速度慢”这个问题,整个推理到渲染加一块,普通显卡,可以做到15FPS的速度,后来我们把重建和AR做了一个结合,用iPad陀螺仪控制渲染的相机位姿,最后有幸获得SIGGRAPH Real-Time Live的Best Show Award (SIGGRAPH 2020 有哪些不容错过的内容?)
但是“姿态鲁棒性”一直没有得到很好的解决。PIFuHD[7]将PIFu做到了4K图片上,把数字人的几何细节又提了一个档次,但还是只能在站立/时装姿势 (fashion pose)下得到满意的结果。ARCH[8]以及ARCH++[9]尝试把问题从姿态空间(pose space)转换到标准空间(canonical space, 把人摆成“大”字)来解决,但这种转换,首先很依赖于姿态估计(HPS)的准确性,其次,由于转换依赖于SMPL自带的蒙皮骨骼权重(skinning weights),这个权重是写死的且定义在裸体上,强行用到穿衣服的人上,由动作带动的衣服褶皱细节就不那么自然。
另外一个思路,就是加几何先验 (geometric prior),通俗点说,就是我给你一个粗糙的人体几何,然后根据图像信息,来雕琢出来一个细致的人体几何。GeoPIFu (+estimated voxel)[10], PaMIR (+voxelized SMPL)[11], S3(+lidar)[12]都有做尝试。我尝试过直接把准确的几何先验 (groundtruth SMPL)灌给PaMIR,但PaMIR依旧不能在训练集中没见过的姿态上(比如舞蹈,运动,功夫,跑酷等)重建出满意的结果。

为什么要提高姿势水平
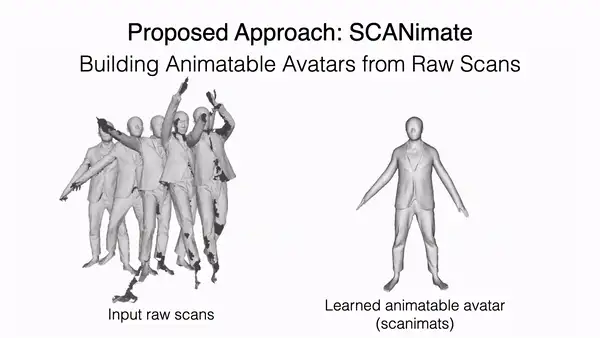
为了彻底打通基于图像的重建(image-based reconstruction)和基于扫描的建模(scan-based modeling)
随着NASA[13], SCANimate[14], SNARF[15], metaAvatar[16], Neural-GIF[17]等一系列工作爆发,如何从动态的三维人体扫描 (3D human scan sequences / 4D scans) 中学出来一个可以被驱动的用神经网络表达的数字人(animatable neural avatar)渐渐成为一个研究热点,而高质量的动态人体扫描的获得,费钱费人工,导致普通用户,或者没有多视角采集设备的团队,很难进入这个领域。

那么,有没有可能,扔掉昂贵且费时费力的扫描流程,用PIFu从视频中做逐帧重建(Images to Meshes),然后把重建结果直接扔给SCANimate做建模呢(Meshes to Avatar)?

理论上,当然是可以的,但是现实却很骨感。症结在于,现有的重建算法,都没有办法在很多样的姿态下保持重建的稳定性,但,数量足够多且姿势各异的三维人体,却是SCANimate构建高质量可驱动数字人的必要前提!这个不难理解——要让一个数字人无论怎么动弹,衣服裤子的褶皱都很真实,如果用数据驱动的思路去做,那么网络得先“看过足够多”类似动作下衣服的形变,才能准确摸索出衣服形变与动作姿势之间的关联。总而言之,真要把Images-Meshes-Avatar这条路走通,非提高姿势水平不可。
如何提高姿势水平
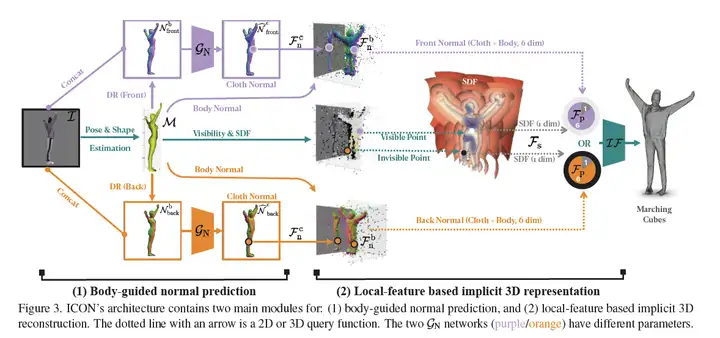
ICON在思路上,借鉴了很多相关工作。比如PIFuHD里面的法向图(Normal Image),以及和PaMIR一样,都用了SMPL body做几何空间约束,这两个信息都是不可或缺的:SMPL body提供了一个粗糙的人体几何,而法向图则包含了丰富的衣服褶皱细节,一粗一细,相得益彰。

然后,问题就来了:
怎么从图像中提取出准确且细致的 normal image?直接从图像中预测的 SMPL body 如果不准确该怎么办?SMPL body 这个几何约束,该怎么用?这是三个独立的问题吗?不是,它们其实是高度相关的。
SMPL辅助normal预测。pix2pix 地从 RGB 猜 normal,要在不同姿态上做到足够泛化,就需要灌进去大量的训练数据。但,既然 SMPL body 已经提供了粗糙的人体几何,这个几何也可以渲染成 body normal 的形式,那么,如果我们把这个 body normal 和 RGB 合并一下,一块扔进网络作为输入,原来 pix2pix 的问题就可以转化为——用 RGB 的细节信息对粗糙的 body normal 进行形变(wraping)和雕琢(carving)最后获得 clothed normal ——这样一个新问题,而这个问题的解决,可以不依赖于大量训练数据。normal帮助优化SMPL。既然 clothed normal 可以从图像中攫取到 SMPL body 没有的几何细节,那么有没有可能用这些信息去反过来优化 SMPL body ?这样,SMPL body 和 clothed normal 就可以左右手互搏,相互裨益迭代优化,body mesh 准了,normal image就对,normal image对了,反过来还可以进一步优化 body mesh,1+1>2,双赢,就是赢两次。扔掉global encoder。最后,SMPL body 和 clothed normal 都有了,即人大致的体型和衣服几何细节都有了,我们真的需要像S3, PaMIR, GeoPIFu 那样,怼一个巨大的全局卷积神经网络(2D/3D global CNN)来提特征,然后用Implicit MLP雕琢出穿衣人的精细外形吗?ICON的答案是,不需要,SDF is all you need开门,放图


下面这张图,展示了ICON整个处理管线。先从图像中预测SMPL body,渲染出正反body normal,与原始图像合并起来,过一个法向预测网络,出正反clothed normal,然后对于三维空间中的点,clothed normal取三维,body normal上取三维(注意,这里是从SMPL mesh上用最近邻取的,而不是从body normal image中取的),SDF取一维,一共七维,直接扔进implict MLP,Marching Cube取一下0.5 level-set等值面,打完收工。
量化指标在 Tab.2 中就不放了,反正现在什么文章都是SOTA。额外多说一句,为了确保比较的绝对公平,我除了用原作者放的模型在测试集上跑了结果,还在ICON的框架内,重新复现了PIFu, PaMIR,确保除了方法本身的差异,其他部分(训练数据,优化策略,网络结构)都保持一致,不引入干扰变量。实验结论原文中有一整页,我用人话概括一下,ICON是SOTA,在离谱的姿势下优势明显,训起来省数据,SMPL不准的时候,加上迭代优化那个模块,甚至要比PaMIR直接在精准SMPL上的结果还要好,总之,都是坠吼的。
多说一句,现在放出来的代码只包括测试代码,但完整的训练代码已经在路上(可以github点个watch等待推送),ICON包括了PIFu, PaMIR以及ICON各种变种的测试+训练代码,而且使用了PyTorch-Lightning框架做代码规范,以后大家要用自己的数据在ICON, PIFu, PaMIR上做训练和测试,只需要基于ICON做点手脚就好。
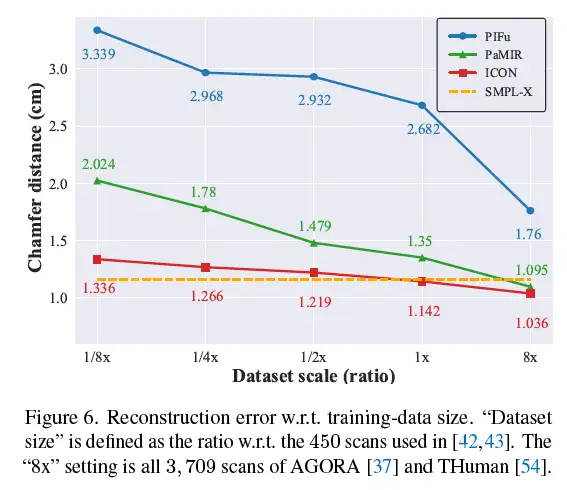
这张图证明了ICON的一个特别突出的优势,就是省钱,毕竟RenderPeople一个就几百块人民币,实在离谱。仅仅给1/8的训练数据(50个3D human scan),ICON重建的质量,就可以超过用接近4000个训练数据训出来的PIFu,也超过了用450个数据训出来的PaMIR。作为一个扔掉了global CNN的极其local的模型,ICON对训练数据量,确实不敏感,而恰恰就是这种钝感,对于提高三维人重建的姿势水平至关重要。
为了充分测试ICON在非常难的姿势上是个什么水平,我从pinterest上找了一些动作非常离谱的图片,武术,跑酷,舞蹈,体育等等,总之,这些动作从未出现在训练集中,也不可能成为训练集(动作转瞬即逝,没法稳定住用仪器进行扫描捕捉),但结果是令人欣慰的,尽管不完美,但至少还是个人形。

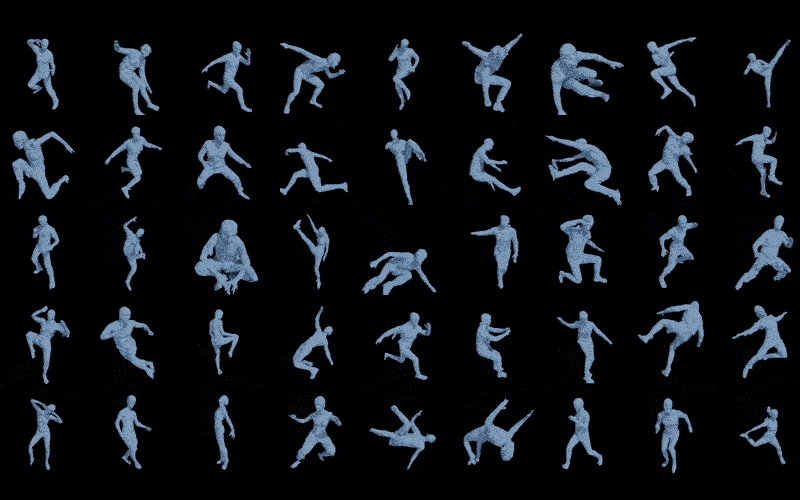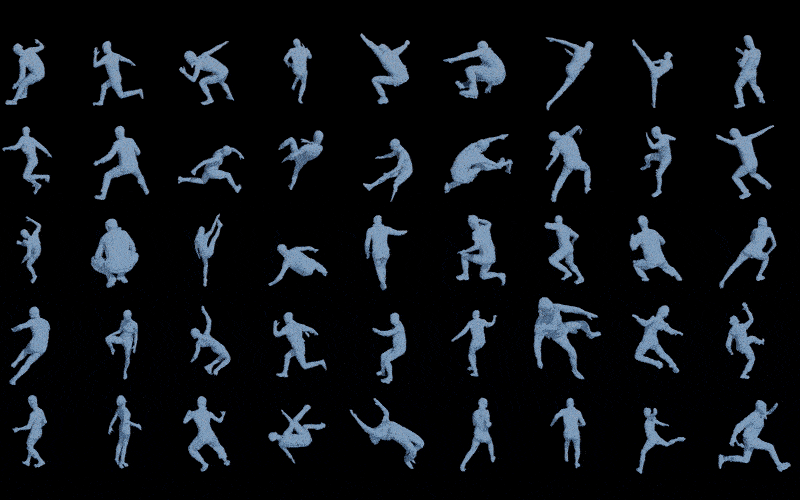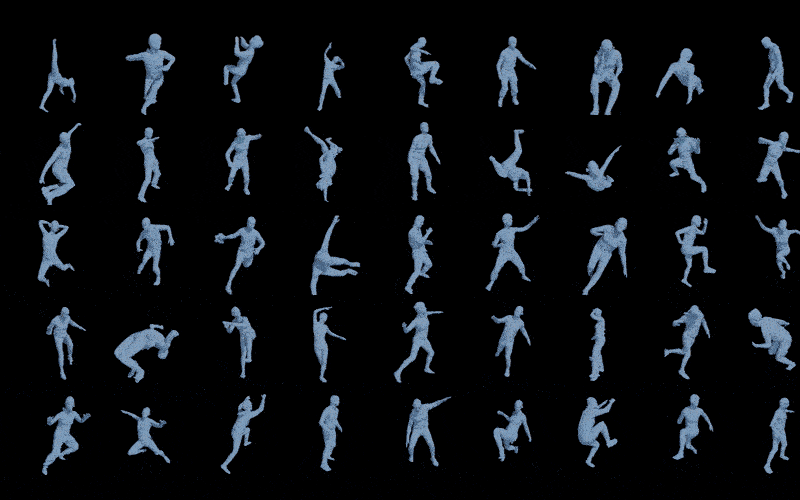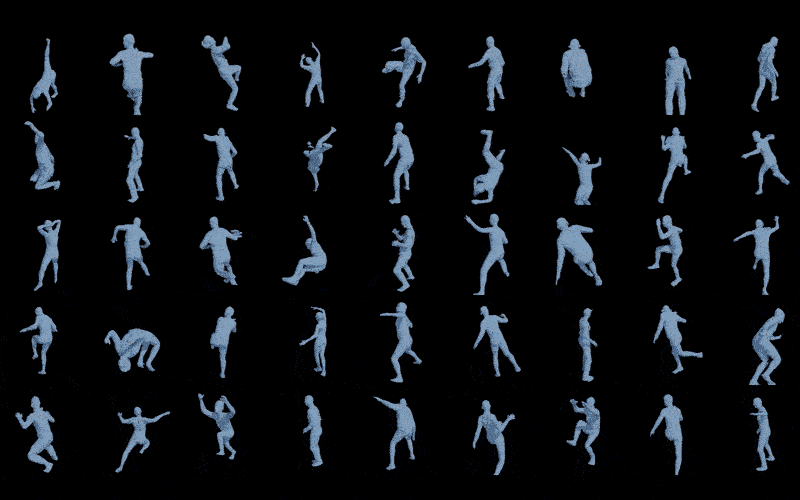
最后,我们按照之前计划的,把Images-Meshes-Avatar的流程跑了一下,还不错。

把我批判一番
ICON确实可以提高姿势水平,但不是尽善尽美,谨遵教员的教诲“对于偶然犯错误的同志,须使用批评和自我批评的方法“,接下来,咱们聊聊,ICON的劣势,都可以谈,没什么不能谈的。
其实原论文及补充材料中对“坏结果”的分析和呈现(Fig.7, Fig.18),已然不怎么遮掩了,但既然文章已经录用,自然可以更坦诚一些。ICON在量化指标上是SOTA,挑几个彼劣我优的例子,不难,但那是给审稿人看的,而对本领域相关研究者而言,“坏结果”往往比“好结果”更能揭示方法的原理和本质。

ICON现有的问题主要集中在这样几块:
鱼和熊掌不可得兼。SMPL prior带来了稳定性,但也破坏了implicit function原有的优势——几何表达的自由性,因此,对于那些离裸体比较远的部分,比如两腿之间的裙子,比如随风飞扬的外套,就挂了。而这些部分,最原始的PIFu不见的做的比ICON差,毕竟PIFu是没有引入任何几何先验的,总之,稳定性vs自由度,是一个tradeoff慢。SMPL-normal迭代优化的设计思路,导致单张图要跑20s才能出来不错的结果,实时性大大折扣性能天花板受制于HPS。重建结果受SMPL准确性影响极大,SMPL-Normal的迭代优化,并不能彻底解决严重的姿势估计错误,ICON现在支持PyMAF[18], PARE[19]以及PIXIE[20]三种HPS,PARE对遮挡好一些,PIXIE手和脸准一些,PyMAF最稳定,但依旧对一些很难的case束手无策。所以,尽管HPS已经被人做烂了,围绕各种corner case一年能出几百篇论文,但我们依然不能说这个问题解决了,也不能说,这个问题没有价值了,至少,对于ICON而言,HPS的准确度,是一切的基础,HPS挂了,迭代优化到猴年马月也没用。几何比法向差。clothed normal的质量和最终重建的人体几何质量,有gap。已经有很多用户和我抱怨这件事了,normal明明看起来很好,但geometry的质量就打了折扣。理论上,重建人体渲染出来的normal image和网络预测出来的clothed normal不应该有那么大差距,这块我还在debug,希望下一个版本可以修复。
历史的进程
基于ICON,接下来还可以做点啥:
ICON++,进一步提升ICON的重建质量,更快更细节更稳定更泛化更通用把ICON用到别的任务中,比如不做人了,做动物,比如用ICON做个数据集,基于数据集,搞个生成模型啥的Wildvideo-ICON, Multiview-ICON, Multiperson-ICON扔掉3D supervision,非监督,自监督,以及训练范式的改进,比如,E2E-ICON开脑洞随机列了一些,一个人肯定是做不过来,如果有同学对这些方向有兴趣,我非常欢迎各种形式的合作(yuliang.xiu@tuebingen.mpg.de)。疫情带来了很多不方便,但也让大家适应了远程协作,能看到这里都是缘分,除了这底下留言,我也开了discord房间,大家畅所欲言。













